---
layout: page
tag: futures and promises
title: "Futures and Promises"
subtitle: "Futures and promises are a popular abstraction for asynchronous programming, especially in the context of distributed systems. We'll cover the motivation for and history of these abstractions, and see how they have evolved over time. We’ll do a deep dive into their differing semantics, and various models of execution. This isn't only history and evolution; we’ll also dive into futures and promises most widely utilized today in languages like JavaScript, Scala, and C++."
by: "Kisalaya Prasad, Avanti Patil, and Heather Miller"
---
## Introduction
As human beings we have the ability to multitask _i.e._ we can walk, talk, and eat at the same time except when sneezing. Sneezing is a blocking activity because it forces you to stop what you’re doing for a brief moment, and then you resume where you left off. One can think of the human sense of multitasking as multithreading in the context of computers.
Consider for a moment a simple computer processor; no parallelism, just the ability to complete one task or process at a time. In this scenario, sometimes the processor is blocked when some blocking operation is called. Such blocking calls can include I/O operations like reading/writing to disk, or sending or receiving packets over the network. And as programmers, we know that blocking calls like I/O can take disproportionately more time than a typical CPU-bound task, like iterating over a list.
The processor can handle blocking calls in two ways:
- **Synchronously**: the processor waits until the blocking call completes its task and returns the result. Afterwards, the processor will move on to processing the next task. _This can oftentimes be problematic because the CPU may not be utilized in an efficient manner; it may wait for long periods of time._
- **Asynchronously**: When tasks are processed asynchronously, CPU time spent waiting in the synchronous case is instead spent processing some other task using a preemptive time sharing algorithm. That is, rather than wait, process some other task instead. Thus, the processor is never left waiting as long as there is more work that can be done.
In the world of programming, many constructs have been introduced in order to help programmers reach ideal levels of resource utilization. Arguably one of the most widely-used of which are futures and/or promises.
In this chapter, we'll do a deep dive into futures and promises, a popular abstraction for doing both synchronous and asynchronous programming. We'll go through the motivation for and history of these abstractions, understand what sort of scenarios they're useful for, and cover how they have evolved over time. We'll cover the various models of execution associated with these abstractions, and finally we'll touch on the futures and promises most widely utilized today in different general purpose programming languages such as JavaScript, Scala, and C++.
## The Basic Idea
As we'll see in subsequent sections, what we choose to call this concept, and its precise definition tends to vary. We will start with the widest possible definition of the concept of a future/promise, and later zoom in and cover the many semantic differences between different languages' interpretations of these constructs.
In the broadest sense,
A future or promise can be thought of as a value that will eventually become available.
Or said another way, it is an abstraction which encodes a notion of time. By choosing to use this construct, it is assumed that your value can now have many possible states, depending on the point in time which we request it. The simplest variation includes two time-dependent states; a future/promise is either:
1. **_completed_/_determined_**: the computation is complete and the future/promise's value is available.
2. **_incomplete_/_undetermined_**: the computation is not yet complete.
As we'll later see, other states have been introduced in some variations of futures/promises to better support needs like error-handling and cancellation.
Importantly, futures/promises typically enable some degree of concurrency. That is, in one of first defitions of futures:
The construct ( future X ) immediately returns a future for the value of the expression X and concurrently begins evaluating X. When the evaluation of X yields a value, that value replaces the future.
Some interpretations of futures/promises have a type associated with them, others not. Typically a future/promise is single-assignment; that is, it can only be written to once. Some interpretations are blocking (synchronous), others are completely non-blocking (asynchronous). Some interpretations must be explicitly _kicked off_ (i.e. manually started), while in other interpretations, computation is started implicitly.
Inspired by functional programming, one of the major distinctions between different interpretations of this construct have to do with _pipelineing_ or _composition_. Some of the more popular interpretations of futures/promises make it possible to _chain_ operations, or define a pipeline of operations to be invoked upon completion of the computation represented by the future/promise. This is in contrast to callback-heavy or more imperative direct blocking approaches.
## Motivation and Uses
The rise of promises and futures as a topic of relevance has for the most part occurred alongside of the rise of parallel and concurrent programming and distributed systems. This follows somewhat naturally, since, as an abstraction which encodes time, futures/promises introduce a nice way to reason about state changes when latency becomes an issue; a common concern faced by programmers when a node must communicate with another node in a distributed system.
However promises and futures are considered useful in a number of other contexts as well, both distributed and not. Some such contexts include:
- **Request-Response Patterns**, such as web service calls over HTTP. A future may be used to represent the value of the response of the HTTP request.
- **Input/Output**, such as UI dialogs requiring user input, or operations such as reading large files from disk. A future may be used to represent the IO call and the resulting value of the IO (e.g., terminal input, array of bytes of a file that was read).
- **Long-Running Computations**. Imagine you would like the process which initiated a long-running computation, such as a complex numerical algorithm, not to wait on the completion of that long-running computation and to instead move on to process some other task. A future may be used to represent this long-running computation and the value of its result.
- **Database Queries**. Like long-running computations, database queries can be time-consuming. Thus, like above, it may be desirable to offload the work of doing the query to another process and move on to processing the next task. A future may be used to represent the query and resulting value of the query.
- **RPC (Remote Procedure Call)**. Network latency is typically an issue when making an RPC call to a server. Like above, it may be desirable to not have to wait on the result of the RPC invocation by instead offloading it to another process. A future may be used to represent the RPC call and its result; when the server responds with a result, the future is completed and its value is the server's response.
- **Reading Data from a Socket** can be time-consuming particularly due to network latency. It may thus be desirable to not to have to wait on incoming data, and instead to offload it to another process. A future may be used to represent the reading operation and the resulting value of what it reads when the future is completed.
- **Timeouts**, such as managing timeouts in a web service. A future representing a timeout could simply return no result or some kind of empty result like the `Unit` type in typed programming languages.
Many real world services and systems today make heavy use of futures/promises in popular contexts such as these, thanks to the notion of a future or a promise having been introduced in popular languages and frameworks such as JavaScript, Node.js, Scala, Java, C++, amongst many others. As we will see in further sections, this proliferation of futures/promises has resulted in futures/promises changing meanings and names over time and across languages.
## Diverging Terminology
_Future_, _Promise_, _Delay_ or _Deferred_ generally refer to roughly the same synchronization mechanism where an object acts as a proxy for as-of-yet unknown result. When the result is available, some other code then gets executed. Over the years, these terms have come to refer to slightly different semantic meanings between languages and ecosystems.
Sometimes, a language may have _one_ construct named future, promise, delay, deferred, etc.
However, in other cases, a language may have _two_ constructs, typically referred to as futures and promises. Languages like Scala, Java, and Dart fall into this category. In this case,
- A `Future` is a read-only reference to a yet-to-be-computed value.
- A `Promise` (or a `CompletableFuture`/`Completer`/etc.) is a single-assignment variable which the `Future` refers to.
In other words, a future is a read-only window to a value written into a promise. You can get the `Future` associated with a `Promise` by calling the `future` method on it, but conversion in the other direction is not possible. Another way to look at it would be, if you _promise_ something to someone, you are responsible for keeping it, but if someone else makes a _promise_ to you, you expect them to honor it in the _future_.
In Scala, they are defined as follows:
A future is a placeholder object for a result that does not yet exist.
A promise is a writable, single-assignment container, which completes a future. Promises can complete the future with a result to indicate success, or with an exception to indicate failure.
An important difference between Scala and Java (6) futures is that Scala futures are asynchronous in nature. Java's future, at least till Java 6, were blocking. Java 7 introduced asynchronous futures to great fanfare.
In Java 8, the `Future` interface has methods to check if the computation is complete, to wait for its completion, and to retrieve the result of the computation when it is complete. `CompletableFutures` can be thought of as a promise, since their value can be explicitly set. However, `CompletableFuture` also implements the `Future` interface allowing it to be used as a `Future` as well. Promises can be thought of as a future with a public set method which the caller (or anybody else) can use to set the value of the future.
In the JavaScript world, JQuery introduces a notion of `Deferred` objects which are used to represent a unit of work which is not yet finished. The `Deferred` object contains a promise object which represents the result of that unit of work. Promises are values returned by a function. The deferred object can also be canceled by its caller.
Like Scala and Java, C# also makes the distinction between the future and promise constructs described above. In C#, futures are called `Task`s, and promises are called `TaskCompletionSource`. The result of the future is available in the read-only property `Task.Result` which returns `T`, and `TaskCompletionSource.Task` has methods to complete the `Task` object with a result of type `T` or with an exception or cancellation. Important to note; `Task`s are asynchronous in C#.
And confusingly, the JavaScript community has standardized on a single construct known as a `Promise` which can be used like other languages' notions of futures. The Promises specification {% cite PromisesAPlus --file futures %} defines only a single interface and leaves the details of completing (or _fulfilling_) the promise to the implementer of the spec. Promises in JavaScript are also asynchronous and able to be pipelined. JavaScript promises are enabled by default in browsers that support ECMAScript 6 (EC6), or are available in a number of libraries such as [Bluebird](http://bluebirdjs.com/docs/getting-started.html) and [Q](https://github.com/kriskowal/q).
As we can see, concepts, semantics, and terminology seem to differ between languages and library implementations of futures/promises. These differences in terminology and semantics arise from the long history and independent language communities that have proliferated the use of futures/promises.
## Brief History
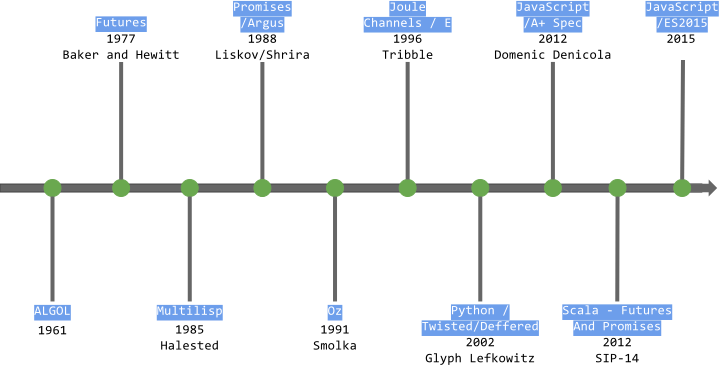
Here's a brief glimpse at a timeline spanning the history of futures and promises as we know them today:
The first concept which eventually led to futures/promises appeared in 1961, with so-called _thunks_. Thunks can be thought of as a primitive, sequential notion of a future or promise. According to its inventor P. Z. Ingerman, thunks are:
A piece of coding which provides an address
Thunks were designed as a way of binding actual parameters to their formal definitions in Algol-60 procedure calls. If a procedure is called with an expression in the place of a formal parameter, the compiler generates a thunk which computes the expression and leaves the address of the result in some standard location. Think of a thunk as a continuation or a function that was intended to be evaluated in a single-threaded environment.
The first mention of Futures was by Baker and Hewitt in a paper on Incremental Garbage Collection of Processes {% cite Hewitt77 --file futures %}. They coined the term, _call-by-futures_, to describe a calling convention in which each formal parameter to a method is bound to a process which evaluates the expression in the parameter in parallel with other parameters. Before this paper, Algol 68 **{% cite missingref --file futures %}** also presented a way to make this kind of concurrent parameter evaluation possible, using the collateral clauses and parallel clauses for parameter binding.
In their paper, Baker and Hewitt introduced a notion of Futures as a 3-tuple representing an expression `E` consisting of:
1. A process which evaluates `E`,
2. A memory location where the result of `E` needs to be stored,
3. A list of processes which are waiting on `E`.
Though importantly, the focus of their work was not on role of futures and the role they play in asynchronous distributed computing. Instead, it was focused on garbage collecting the processes which evaluate expressions that were not needed by the function.
The Multilisp language {% cite Multilisp --file futures %}, presented by Halestead in 1985 built upon this call-by-future with a future annotation. In Multilisp, binding a variable to a future expression would in turn create a new process which evaluates that expression and binds it to the variable reference which represents its (eventual) result. That is, Multilisp introduced a way to compute arbitrary expressions concurrently in a new process. This made it possible to move past the actual computation and continue processing without waiting for the future to complete. If the result value of the future is never used, the initiating process will not block, thus eliminating a potential source of deadlock. MultiLisp also included a lazy future variant, called _delay_, which would only be evaluated the first time the value is required elsewhere in the program.
This design of futures in Multilisp in turn influenced a construct dubbed _promises_ in the Argus programming language {% cite Promises88 Argus88 --file futures %} by Liskov and Shrira in 1988. Like futures in MultiLisp, promises in Argus intended to be a placeholder for the result of a value that will be available in the future. Unlike Multilisp which was focused on single-machine concurrency, however, Argus was designed to facilitate distributed programming, and in particular focused on promises as a way to integrate _asynchronous_ RPC into the Argus programming language. Importantly, promises were extended beyond futures in Multilisp through the introduction of types to promises. Therefore, in Argus, when a call to `promise` is made, a promise is created which immediately returns, and a type-safe asynchronous RPC call is made in a new process. When the RPC completes, the returned value can be claimed by the caller.
Argus also introduced call streams, which can be thought of as a way to enforce an ordering of concurrently executing calls. A sender and a receiver are connected by a stream, over which it is possible make normal (synchronous) RPC calls, or _stream calls_, in which the sender may make more calls before receiving the reply. The underlying runtime however ensures that, despite the non-blocking stream calls fired off, that all calls and subsequent replies happen in call order. That is, call-streams ensure exactly-once, ordered delivery. Argus also introduces constructs to _compose_ call-streams, in order to build up pipelines of computation, or directed acyclic graphs (DAGs) of computation. These semantics are an early precursor to what we refer to today as _promise pipelining_.
E is an object-oriented programming language for secure distributed computing {% cite ELang --file futures %}, created by Mark S. Miller, Dan Bornstein, and others at Electric Communities in 1997. A major contribution of E is its interpretation and implementation of promises. It traces its routes to Joule {% cite Joule --file futures %}, a dataflow programming language predecessor to E. Importantly, E introduced an _eventually_ operator, `* <- *` which enabled what is called an eventual send in E; that is, the program doesn't wait for the operation to complete and moves to next sequential statement. This is in contrast to the expected semantics of an _immediate call_ which looks like a normal method invocation in E. Eventual sends queue a pending delivery and complete immediately, returning a promise. A pending delivery includes a resolver for the promise. Subsequent messages can also be eventually sent to a promise before it is resolved. In this case, these messages are queued up and forwarded once the promise is resolved. That is, once we have a promise, we are able to chain make several pipelined eventual sends as if the initial promise was already resolved. This notion of _promise pipelining_ {% cite PromisePipe07 --file futures %} has been adopted by a majority of contemporary futures/promises interpretations.
Futures and promises remained primarily an academic fascination until the early 2000s, upon the rise of web application development, networked system development, and an increased need for responsive user interfaces.
Among the mainstream programming languages, Python was perhaps the first, in 2002, to get a library which introduced a construct along the same lines as E’s promises in the Twisted library {% cite Twisted --file futures %}. Twisted introduced the notion of _Deferred_ objects, are used to receive the result of an operation not yet completed. In Twisted, deferred objects are just like normal first-class objects; they can be passed along anywhere a normal object can, the only difference is that deferred objects don't have values. Deferred objects support callbacks, which are called once the result of the operation is complete.
Perhaps most famous in recent memory is that of promises in JavaScript. In 2007, inspired by Python’s Twisted library, the authors of the Dojo Toolkit came up a JavaScript implementation of Twisted's deferred objects, known as `dojo.Deferred`. This in turn inspired Kris Zyp to propose the CommonJS Promises/A spec in 2009 {% cite PromisesA --file futures %}. The same year, Ryan Dahl introduced Node.js. In it’s early versions, Node.js used promises in its non-blocking API. However, when Node.js moved away from promises to its now familiar error-first callback API (the first argument for the callback should be an error object), it left a void to fill for a promises API. [Q.js](https://github.com/kriskowal/q) is an implementation of Promises/A spec by Kris Kowal around this time {% cite Qjs --file futures %}. The [FuturesJS](https://github.com/FuturesJS/FuturesJS) library by AJ O'Neal was another library which aimed to solve flow-control problems without using Promises in the strictest of senses. In 2011, JQuery v1.5 introduced Promises to its wider and ever-growing audience. However, JQuery's promises API was subtly different than the Promises/A spec {% cite JQueryPromises --file futures %}. With the rise of HTML5 and different APIs, there came a problem of different and messy interfaces which added to the already infamous callback hell. The Promises/A+ spec {% cite PromisesAPlus --file futures %} aimed to solve this problem. Following the broad community acceptance of the Promises/A+ spec, promises were finally made a part of the ECMAScript® 2015 Language Specification {% cite Ecmascript15 --file futures %}. However, a lack of backward compatibility and additional features missing in the Promises/A+ spec means that libraries like [BlueBird](http://bluebirdjs.com/docs/getting-started.html) and [Q.js](https://github.com/kriskowal/q) still have a place in the JavaScript ecosystem.
## Semantics of Execution
As architectures and runtimes have developed and changed over the years, so too have the techniques for implementing futures/promises such that the abstraction translates into efficient utilization of system resources. In this section, we'll cover the three primary executions models upon which futures/promises are built on top of in popular languages and libraries. That is, we'll see the different ways in which futures and promises actually get executed and resolved underneath their APIs.
### Thread Pools
A thread pool is an abstraction that gives users access to a group of ready, idle threads which can be given work. Thread pool implementations take care of worker creation, management, and scheduling, which can easily become tricky and costly if not handled carefully. Thread pools come in many different flavors, with many different techniques for scheduling and executing tasks, and with fixed numbers of threads or the ability of the pool to dynamically resize itself depending on load.
A classic thread pool implementation is Java's `Executor`, which is an object which executes the `Runnable` tasks. `Executor`s provide a way of abstracting out how the details of how a task will actually run. These details, like selecting a thread to run the task, how the task is scheduled are managed by the underlying implementation of the `Executor` interface.
Similar to `Executor`, Scala includes is a `ExecutionContext`s as part of the `scala.concurrent` package. The basic intent behind Scala's `ExecutionContext` is the same as Java's `Executor`; it is responsible for efficiently executing computations concurrently without requiring the user of the pool to have to worry about things like scheduling. Importantly, `ExecutionContext` can be thought of as an interface; that is, it is possible to _swap in_ different underlying thread pool implementations and keep the same thread pool interface.
While it's possible to use different thread pool implementations, Scala's default `ExecutionContext` implementation is backed by Java's `ForkJoinPool`; a thread pool implementation that features a work-stealing algorithm in which idle threads pick up tasks previously scheduled to other busy threads. The `ForkJoinPool` is a popular thread pool implementation due to its improved performance over `Executor`s, its ability to better avoid pool-induced deadlock, and for minimizing the amount of time spent switching between threads.
Scala's futures (and promises) are based on this `ExecutionContext` interface to an underlying thread pool. While typically users use the underlying default `ExecutionContext` which is backed by a `ForkJoinPool`, users may also elect to provide (or implement) their own `ExecutionContext` if they need a specific behavior, like blocking futures.
In Scala, every usage of a future or promise requires some kind of `ExecutionContext` to be passed along. This parameter is implicit, and is usually `ExecutionContext.global` (the default underlying `ForkJoinPool` `ExecutionContext`). For example, a creating and running a basic future:
```scala
implicit val ec = ExecutionContext.global
val f : Future[String] = Future { “hello world” }
```
In this example, the global execution context is used to asynchronously run the created future. As mentioned earlier, the `ExecutionContext` parameter to the `Future` is _implicit_. That means that if the compiler finds an instance of an `ExecutionContext` in so-called _implicit scope_, it is automatically passed to the call to `Future` without the user having to explicitly pass it. In the example above, `ec` is put into implicit scope through the use of the `implicit` keyword when declaring `ec`.
As mentioned earlier, futures and promises in Scala are _asynchronous_, which is achieved through the use of callbacks. For example:
```scala
implicit val ec = ExecutionContext.global
val f = Future {
Http("http://api.fixed.io/latest?base=USD").asString
}
f.onComplete {
case Success(response) => println(response)
case Failure(t) => println(t.getMessage())
}
```
In this example, we first create a future `f`, and when it completes, we provide two possible expressions that can be invoked depending on whether the future was executed successfully or if there was an error. In this case, if successful, we get the result of the computation an HTTP string, and we print it. If an exception was thrown, we get the message string contained within the exception and we print that.
So, how does it all work together?
As we mentioned, Futures require an `ExecutionContext`, which is an implicit parameter to virtually all of the futures API. This `ExecutionContext` is used to execute the future. Scala is flexible enough to let users implement their own Execution Contexts, but let’s talk about the default `ExecutionContext`, which is a `ForkJoinPool`.
`ForkJoinPool` is ideal for many small computations that spawn off and then come back together. Scala’s `ForkJoinPool` requires the tasks submitted to it to be a `ForkJoinTask`. The tasks submitted to the global `ExecutionContext` is quietly wrapped inside a `ForkJoinTask` and then executed. `ForkJoinPool` also supports a possibly blocking task, using the `ManagedBlock` method which creates a spare thread if required to ensure that there is sufficient parallelism if the current thread is blocked. To summarize, `ForkJoinPool` is an really good general purpose `ExecutionContext`, which works really well in most of the scenarios.
### Event Loops
Modern platforms and runtimes typically rely on many underlying system layers to operate. For example, there’s an underlying file system, a database system, and other web services that may be relied on by a given language implementation, library, or framework. Interaction with these components typically involves a period where we’re doing nothing but waiting for the response. This can be a very large waste of computing resources.
JavaScript is a single threaded asynchronous runtime. Now, conventionally async programming is generally associated with multi-threading, but we’re not allowed to create new threads in JavaScript. Instead, asynchronicity in JavaScript is achieved using an event-loop mechanism.
JavaScript has historically been used to interact with the DOM and user interactions in the browser, and thus an event-driven programming model was a natural fit for the language. This has scaled up surprisingly well in high throughput scenarios in Node.js.
The general idea behind event-driven programming model is that the logic flow control is determined by the order in which events are processed. This is underpinned by a mechanism which is constantly listening for events and fires a callback when it is detected. This is the JavaScript’s event loop in a nutshell.
A typical JavaScript engine has a few basic components. They are :
- **Heap**
Used to allocate memory for objects
- **Stack**
Function call frames go into a stack from where they’re picked up from top to be executed.
- **Queue**
A message queue holds the messages to be processed.
Each message has a callback function which is fired when the message is processed. These messages can be generated by user actions like button clicks or scrolling, or by actions like HTTP requests, request to a database to fetch records or reading/writing to a file.
Separating when a message is queued from when it is executed means the single thread doesn’t have to wait for an action to complete before moving on to another. We attach a callback to the action we want to do, and when the time comes, the callback is run with the result of our action. Callbacks work good in isolation, but they force us into a continuation passing style of execution, what is otherwise known as Callback hell.
```javascript
getData = function(param, callback){
$.get('http://example.com/get/'+param,
function(responseText){
callback(responseText);
});
}
getData(0, function(a){
getData(a, function(b){
getData(b, function(c){
getData(c, function(d){
getData(d, function(e){
// ...
});
});
});
});
});
```
VS
```javascript
getData = function(param, callback){
return new Promise(function(resolve, reject) {
$.get('http://example.com/get/'+param,
function(responseText){
resolve(responseText);
});
});
}
getData(0).then(getData)
.then(getData)
.then(getData)
.then(getData);
```
> **Programs must be written for people to read, and only incidentally for machines to execute.** - *Harold Abelson and Gerald Jay Sussman*
Promises are an abstraction which make working with async operations in JavaScript much more fun. Callbacks lead to inversion of control, which is difficult to reason about at scale. Moving on from a continuation passing style, where you specify what needs to be done once the action is done, the callee simply returns a Promise object. This inverts the chain of responsibility, as now the caller is responsible for handling the result of the promise when it is settled.
The ES2015 spec specifies that “promises must not fire their resolution/rejection function on the same turn of the event loop that they are created on.” This is an important property because it ensures deterministic order of execution. Also, once a promise is fulfilled or failed, the promise’s value MUST not be changed. This ensures that a promise cannot be resolved more than once.
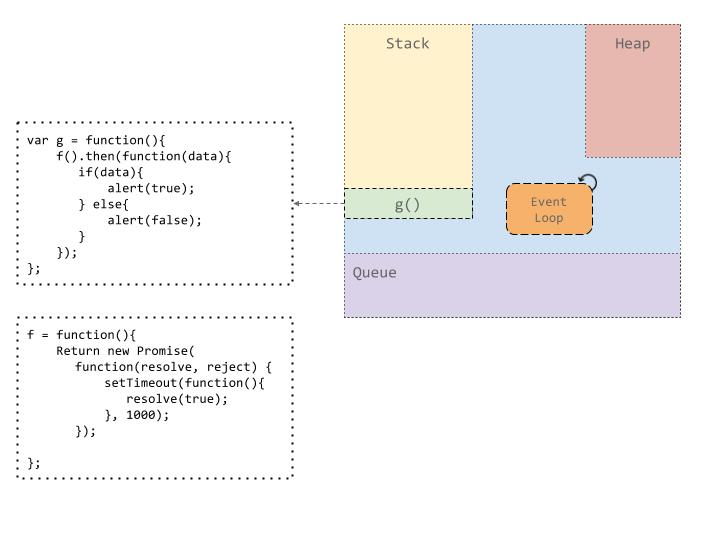
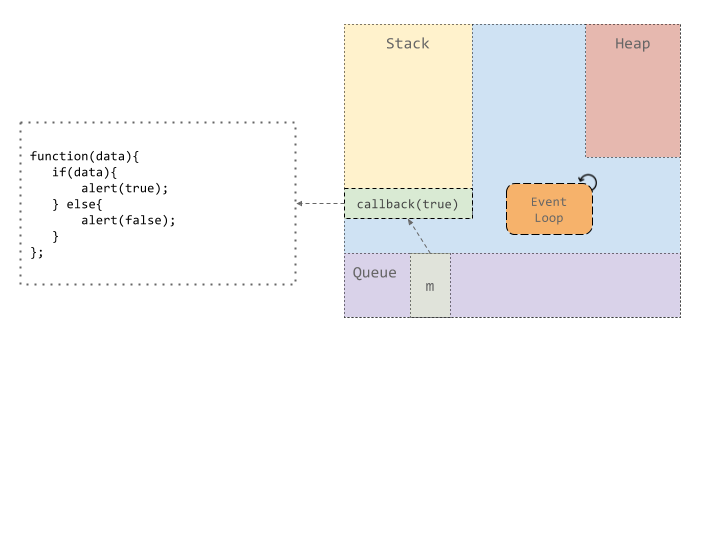
Let’s take an example to understand the promise resolution workflow as it happens inside the JavaScript Engine.
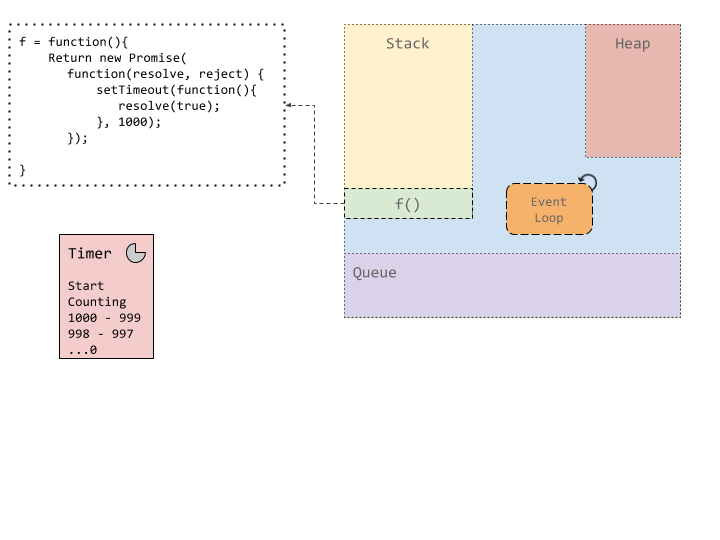
Suppose we execute a function, here `g()` which in turn, calls another function `f()`. Function `f` returns a promise, which, after counting down for 1000 ms, resolves the promise with a single value, true. Once `f` gets resolved, a value `true` or `false` is alerted based on the value of the promise.
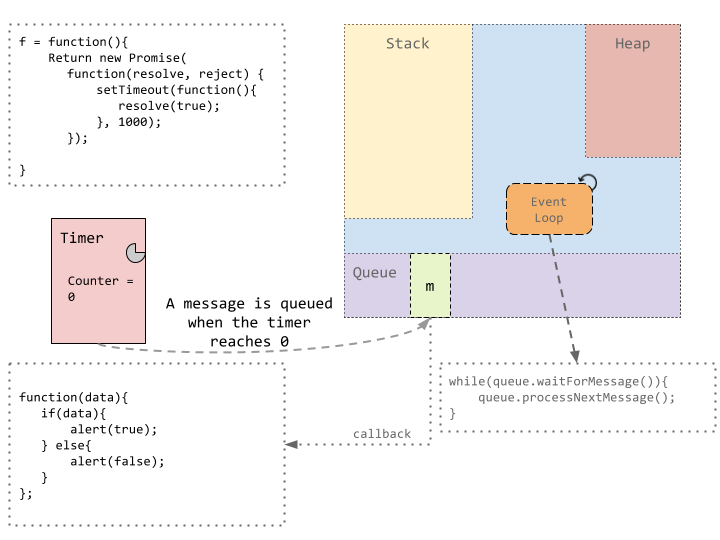
Now, JavaScript’s runtime is single threaded. This statement is true, and not true. The thread which executes the user code is single threaded. It executes what is on top of the stack, runs it to completion, and then moves onto what is next on the stack. But, there are also a number of helper threads which handle things like network or timer/settimeout type events. This timing thread handles the counter for setTimeout.
Once the timer expires, the timer thread puts a message on the message queue. The queued up messages are then handled by the event loop. The event loop as described above, is simply an infinite loop which checks if a message is ready to be processed, picks it up and puts it on the stack for it’s callback to be executed.
Here, since the future is resolved with a value of `true`, we are alerted with a value `true` when the callback is picked up for execution.
We’ve ignored the heap here, but all the functions, variables and callbacks are stored on heap.
As we’ve seen here, even though JavaScript is said to be single threaded, there are number of helper threads to help main thread do things like timeout, UI, network operations, file operations etc.
Run-to-completion helps us reason about the code in a nice way. Whenever a function starts, it needs to finish before yielding the main thread. The data it accesses cannot be modified by someone else. This also means every function needs to finish in a reasonable amount of time, otherwise the program seems hung. This makes JavaScript well suited for I/O tasks which are queued up and then picked up when finished, but not for data processing intensive tasks which generally take long time to finish.
We haven’t talked about error handling, but it gets handled the same exact way, with the error callback being called with the error object the promise is rejected with.
Event loops have proven to be surprisingly performant. When network servers are designed around multithreading, as soon as you end up with a few hundred concurrent connections, the CPU spends so much of its time task switching that you start to lose overall performance. Switching from one thread to another has overhead which can add up significantly at scale. Apache used to choke even as low as a few hundred concurrent users when using a thread per connection while Node.js can scale up to a 100,000 concurrent connections based on event loops and asynchronous IO.
### Thread Model
The Oz programming language introduced an idea of dataflow concurrency model. In Oz, whenever the program comes across an unbound variable, it waits for it to be resolved. This dataflow property of variables helps us write threads in Oz that communicate through streams in a producer-consumer pattern. The major benefit of dataflow based concurrency model is that it’s deterministic - same operation called with same parameters always produces the same result. It makes it a lot easier to reason about concurrent programs, if the code is side-effect free.
Alice ML is a dialect of Standard ML with support for lazy evaluation, concurrent, distributed, and constraint programming. The early aim of Alice project was to reconstruct the functionalities of Oz programming language on top of a typed programming language. Building on the Standard ML dialect, Alice also provides concurrency features as part of the language through the use of a future type. Futures in Alice represent an undetermined result of a concurrent operation. Promises in Alice ML are explicit handles for futures.
Any expression in Alice can be evaluated in it's own thread using spawn keyword. Spawn always returns a future which acts as a placeholder for the result of the operation. Futures in Alice ML can be thought of as functional threads, in a sense that threads in Alice always have a result. A thread is said to be touching a future if it performs an operation that requires the value future is a placeholder for. All threads touching a future are blocked until the future is resolved. If a thread raises an exception, the future is failed and this exception is re-raised in the threads touching it. Futures can also be passed along as values. This helps us achieve the dataflow model of concurrency in Alice.
Alice also allows for lazy evaluation of expressions. Expressions preceded with the lazy keyword are evaluated to a lazy future. The lazy future is evaluated when it is needed. If the computation associated with a concurrent or lazy future ends with an exception, it results in a failed future. Requesting a failed future does not block, it simply raises the exception that was the cause of the failure.
## Implicit vs. Explicit Promises
We define implicit promises as ones where we don’t have to manually trigger the computation vs Explicit promises where we have to trigger the resolution of future manually, either by calling a start function or by requiring the value. This distinction can be understood in terms of what triggers the calculation: With implicit promises, the creation of a promise also triggers the computation, while with explicit futures, one needs to triggers the resolution of a promise. This trigger can in turn be explicit, like calling a start method, or implicit, like lazy evaluation where the first use of a promise’s value triggers its evaluation.
The idea for explicit futures were introduced in the Baker and Hewitt paper. They’re a little trickier to implement, and require some support from the underlying language, and as such they aren’t that common. The Baker and Hewitt paper talked about using futures as placeholders for arguments to a function, which get evaluated in parallel, but when they’re needed. MultiLisp also had a mechanism to delay the evaluation of the future to the time when it's value is first used, using the defer construct. Lazy futures in Alice ML have a similar explicit invocation mechanism, the first thread touching a future triggers its evaluation.
An example of explicit futures would be (from AliceML):
```
fun enum n = lazy n :: enum (n+1)
```
This example generates an infinite stream of integers and if stated when it is created, will compete for the system resources.
Implicit futures were introduced originally by Friedman and Wise in a paper in 1978. The ideas presented in that paper inspired the design of promises in MultiLisp. Futures are also implicit in Scala and JavaScript, where they’re supported as libraries on top of the core languages. Implicit futures can be implemented this way as they don’t require support from language itself. Alice ML’s concurrent futures are also an example of implicit invocation.
In Scala, we can see an example of an implicit future when making an HTTP request.
```scala
val f = Future {
Http("http://api.fixer.io/latest?base=USD").asString
}
f onComplete {
case Success(response) => println(response.body)
case Failure(t) => println(t)
}
```
This sends the HTTP call as soon as it the Future is created. In Scala, although the futures are implicit, Promises can be used to have an explicit-like behavior. This is useful in a scenario where we need to stack up some computations and then resolve the Promise.
```scala
val p = Promise[Foo]()
p.future.map( ... ).filter( ... ) foreach println
p.complete(new Foo)
```
Here, we create a Promise, and complete it later. Between creation and completion we stack up a set of computations which then get executed once the promise is completed.
## Promise Pipelining
One of the criticism of traditional RPC systems would be that they’re blocking. Imagine a scenario where you need to call an API ‘A’ and another API ‘B’, then aggregate the results of both the calls and use that result as a parameter to another API ‘C’. Now, the logical way to go about doing this would be to call A and B in parallel, then once both finish, aggregate the result and call C. Unfortunately, in a blocking system, the way to go about is call A, wait for it to finish, call B, wait, then aggregate and call C. This seems like a waste of time, but in absence of asynchronicity, it is impossible. Even with asynchronicity, it gets a little difficult to manage or scale up the system linearly. Fortunately, we have promises.
Futures/Promises can be passed along, waited upon, or chained and joined together. These properties helps make life easier for the programmers working with them. This also reduces the latency associated with distributed computing. Promises enable dataflow concurrency, which is also deterministic, and easier to reason about.
The history of promise pipelining can be traced back to the call-streams in Argus. In Argus, call-streams are a mechanism for communication between distributed components. The communicating entities, a sender and a receiver are connected by a stream, and sender can make calls to receiver over it. Streams can be thought of as RPC, except that these allow callers to run in parallel with the receiver while processing the call. When making a call in Argus, the caller receives a promise for the result. In the paper on Promises by Liskov and Shrira, they mention that having integrated Promises into call streams, next logical step would be to talk about stream composition. This means arranging streams into pipelines where output of one stream can be used as input of the next stream. They talk about composing streams using fork and coenter.
Channels in Joule were a similar idea, providing a channel which connects an acceptor and a distributor. Joule was a direct ancestor to E language, and talked about it in more detail.
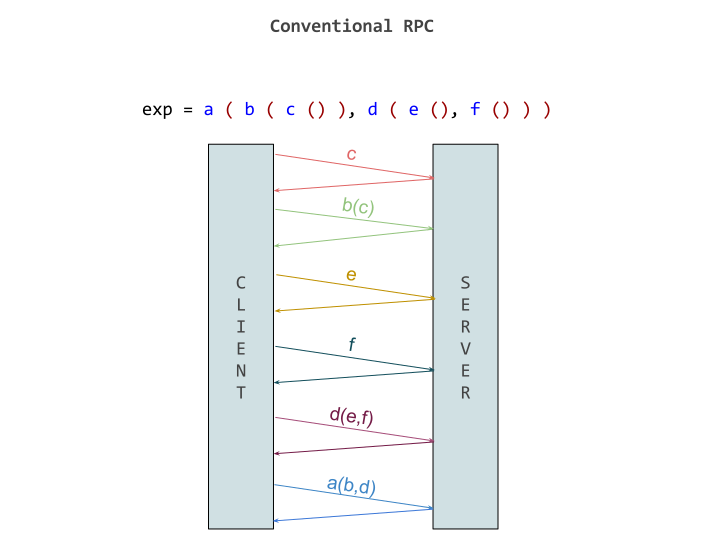
```
t3 := (x <- a()) <- c(y <- b())
t1 := x <- a()
t2 := y <- b()
t3 := t1 <- c(t2)
```
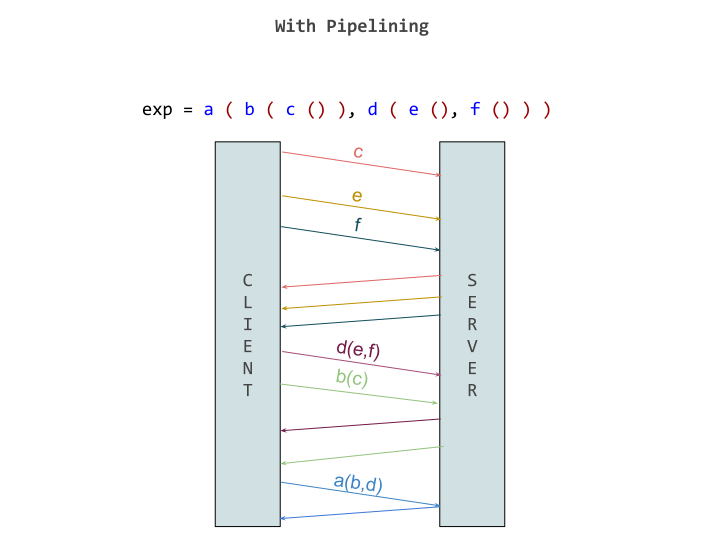
Without pipelining in E, this call will require three round trips. First to send `a()` to `x`, then `b()` to `y` then finally `c` to the result `t1` with `t2` as an argument. But with pipelining, the later messages can be sent with promises as result of earlier messages as argument. This allowed sending all the messages together, thereby saving the costly round trips. This is assuming `x` and `y` are on the same remote machine, otherwise we can still evaluate `t1` and `t2` parallely.
Notice that this pipelining mechanism is different from asynchronous message passing, as in asynchronous message passing, even if `t1` and `t2` get evaluated in parallel, to resolve `t3` we still wait for `t1` and `t2` to be resolved, and send it again in another call to the remote machine.
Modern promise specifications, like one in JavaScript comes with methods which help working with promise pipelining easier. In JavaScript, a `Promise.all` method is provided, which takes in an iterable and returns a new `Promise` which gets resolved when all the promises in the iterable get resolved. There’s also a `Promise.race` method, which returns a promise which is resolved when the first promise in the iterable gets resolved. Examples using these methods are shown below.
```javascript
var a = Promise.resolve(1);
var b = new Promise(function (resolve, reject) {
setTimeout(resolve, 100, 2);
});
Promise.all([p1, p2]).then(values => {
console.log(values); // [1,2]
});
Promise.race([p1, p2]).then(function(value) {
console.log(value); // 1
});
```
In Scala, futures have an `onSuccess` method which acts as a callback to when the future is complete. This callback itself can be used to sequentially chain futures together. But this results in bulkier code. Fortunately, the Scala API has combinators which allow for easier combination of results from futures. Examples of combinators are `map`, `flatMap`, `filter`, `withFilter`.
## Handling Errors
If the world ran without errors we would rejoice in unison, but this is not the case in the programming world. When you run a program you either receive an expected output or an error. Error can be defined as wrong output or an exception. In a synchronous programming model, the most logical way of handling errors is a `try...catch` block.
```javascript
try {
do something1;
do something2;
do something3;
// ...
} catch (exception) {
HandleException;
}
```
Unfortunately, the same thing doesn’t directly translate to asynchronous code.
```javascript
foo = doSomethingAsync();
try {
foo();
// This doesn’t work as the error might not have been thrown yet
} catch (exception) {
handleException;
}
```
Although most of the earlier papers did not talk about error handling, the Promises paper by Liskov and Shrira did acknowledge the possibility of failure in a distributed environment. To put this in Argus's perspective, the 'claim' operation waits until the promise is ready. Then it returns normally if the call terminated normally, and otherwise it signals the appropriate 'exception', e.g.
```
y: real := pt$claim(x)
except when foo: ...
when unavailable(s: string): .
when failure(s: string): . .
end
```
Here x is a promise object of type pt; the form pi$claim illustrates the way Argus identifies an operation of a type by concatenating the type name with the operation name. When there are communication problems, RPCs in Argus terminate either with the 'unavailable' exception or the 'failure' exception.
* **Unavailable** means that the problem is temporary e.g. communication is impossible right now.
* **Failure** means that the problem is permanent e.g. the handler’s guardian does not exist.
Thus stream calls (and sends) whose replies are lost because of broken streams will terminate with one of these exceptions. Both exceptions have a string argument that explains the reason for the failure, e.g., `future("handler does not exist")` or `unavailable("cannot communicate")`. Since any call can fail, every handler can raise the exceptions failure and unavailable. In this paper they also talked about propagation of exceptions from the called procedure to the caller. In the paper about the E language they talk about broken promises and setting a promise to the exception of broken references.
### Modern Languages
In modern languages like Scala, Promises generally come with two callbacks. One to handle the success case and other to handle the failure. e.g.
```scala
f onComplete {
case Success(data) => handleSuccess(data)
case Failure(e) => handleFailure(e)
}
```
In Scala, the `Try` type represents a computation that may either result in an exception, or return a successfully computed value. For example, `Try[Int]` represents a computation which can either result in `Int` if it's successful, or return a `Throwable` if something is wrong.
```scala
val a: Int = 100
val b: Int = 0
def divide: Try[Int] = Try(a/b)
divide match {
case Success(v) =>
println(v)
case Failure(e) =>
println(e) // java.lang.ArithmeticException: / by zero
}
```
The `Try` type can be pipelined, allowing for catching exceptions and recovering from them along the way.
A similar pattern for handling exceptions can be seen in JavaScript.
```javascript
promise.then(function (data) {
// success callback
console.log(data);
}, function (error) {
// failure callback
console.error(error);
});
```
Scala futures exception handling:
When asynchronous computations throw unhandled exceptions, futures associated with those computations fail. Failed futures store an instance of `Throwable` instead of the result value. Futures provide the onFailure callback method, which accepts a PartialFunction to be applied to a `Throwable`. `TimeoutException`, `scala.runtime.NonLocalReturnControl[]` and `ExecutionException` exceptions are treated differently
Scala promises exception handling:
When failing a promise with an exception, three subtypes of `Throwable` are handled specially. If the `Throwable` used to break the promise is a `scala.runtime.NonLocalReturnControl`, then the promise is completed with the corresponding value. If the `Throwable` used to break the promise is an instance of `Error`, `InterruptedException`, or `scala.util.control.ControlThrowable`, the `Throwable` is wrapped as the cause of a new `ExecutionException` which, in turn, is failing the promise.
To handle errors with asynchronous methods and callbacks, the error-first callback style (which we've seen before, and has also been adopted by Node.js) is the most common convention. Although this works, but it is not very composable, and eventually takes us back to what is called callback hell. Fortunately, Promises allow asynchronous code to apply structured error handling. The `Promises.then` method takes in two callbacks, a `onFulfilled` to handle when a promise is resolved successfully and a onRejected to handle if the promise is rejected.
```javascript
var p = new Promise(function(resolve, reject) {
resolve(100);
});
p.then(function(data) {
console.log(data); // 100
}, function(error) {
console.err(error);
});
var q = new Promise(function(resolve, reject) {
reject(new Error(
{'message':'Divide by zero'}
));
});
q.then(function(data) {
console.log(data);
}, function(error) {
console.err(error); // {'message':'Divide by zero'}
});
```
Promises also have a catch method, which work the same way as onFailure callback, but also help deal with errors in a composition. Exceptions in promises behave the same way as they do in a synchronous block of code : they jump to the nearest exception handler.
```javascript
function work(data) {
return Promise.resolve(data + "1");
}
function error(data) {
return Promise.reject(data + "2");
}
function handleError(error) {
return error + "3";
}
work("")
.then(work)
.then(error)
.then(work) // this will be skipped
.then(work, handleError)
.then(check);
function check(data) {
console.log(data == "1123");
return Promise.resolve();
}
```
The same behavior can be written using catch block.
```javascript
work("")
.then(work)
.then(error)
.then(work)
.catch(handleError)
.then(check);
function check(data) {
console.log(data == "1123");
return Promise.resolve();
}
```
## Futures and Promises in Action
### Twitter Finagle
Finagle is a protocol-agnostic, asynchronous RPC system for the JVM that makes it easy to build robust clients and servers in Java, Scala, or any other JVM language. It uses Futures to encapsulate concurrent tasks. Finagle introduces two other abstractions built on top of Futures to reason about distributed software:
- **Services** are asynchronous functions which represent system boundaries.
- **Filters** are application-independent blocks of logic like handling timeouts and authentication.
In Finagle, operations describe what needs to be done, while the actual execution is left to be handled by the runtime. The runtime comes with a robust implementation of connection pooling, failure detection and recovery and load balancers.
An example of a `Service`:
```scala
val service = new Service[HttpRequest, HttpResponse] {
def apply(request: HttpRequest) =
Future(new DefaultHttpResponse(HTTP_1_1, OK))
}
```
A timeout filter can be implemented as:
```scala
def timeoutFilter(d: Duration) = {
(req, service) => service(req).within(d)
}
```
### Correctables
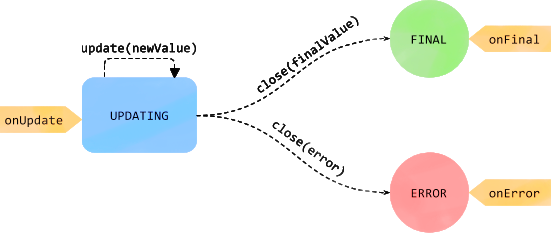
Correctables were introduced by Rachid Guerraoui, Matej Pavlovic, and Dragos-Adrian Seredinschi at OSDI ‘16, in a paper titled Incremental Consistency Guarantees for Replicated Objects. As the title suggests, Correctables aim to solve the problems with consistency in replicated objects. They provide incremental consistency guarantees by capturing successive changes to the value of a replicated object. Applications can opt to receive a fast but possibly inconsistent result if eventual consistency is acceptable, or to wait for a strongly consistent result. Correctables API draws inspiration from, and builds on the API of Promises. Promises have a two state model to represent an asynchronous task, it starts in blocked state and proceeds to a ready state when the value is available. This cannot represent the incremental nature of correctables. Instead, Correctables have a updating state when they start. From there on, they remain in an updating state during intermediate updates, and when the final result is available, they transition to final state. If an error occurs in between, they move into an error state. Each state change triggers a callback.
### Folly Futures
Folly is a library by Facebook for asynchronous C++ inspired by the implementation of Futures by Twitter for Scala. It builds upon the Futures in the C++11 Standard. Like Scala’s futures, they also allow for implementing a custom executor which provides different ways of running a Future (thread pool, event loop etc).
### Node.js Fibers
Fibers provide coroutine support for V8 and Node.js. Applications can use Fibers to allow users to write code without using a ton of callbacks, without sacrificing the performance benefits of asynchronous IO. Think of fibers as light-weight threads for Node.js where the scheduling is in the hands of the programmer. The node-fibers library doesn’t recommend using raw API and code together without any abstractions, and provides a Futures implementation which is ‘fiber-aware’.
## References
{% bibliography --file futures %}